Find And Fix Index Coverage Errors In Google Search Console

Ideally, index coverage is a report in which the Google search console shows the crawling and indexing status of the URLs discovered by Google for your website. It helps keep track of your website's indexing status and keeps you updated about the technical glitches preventing your web pages from being indexed and crawled correctly. When you regularly check the index coverage report, you can spot and understand how to address them.
Things to know about the index coverage report

The index coverage report is available in the Google search console. It generally shows which pages have been successfully indexed for you by Google and which pages have not been indexed due to some errors. In addition, you can get more details about the error for each of the pages, and you also have the option to request Google to reindex them or reindex the entire website as a whole.
How can you find errors with the index coverage report?
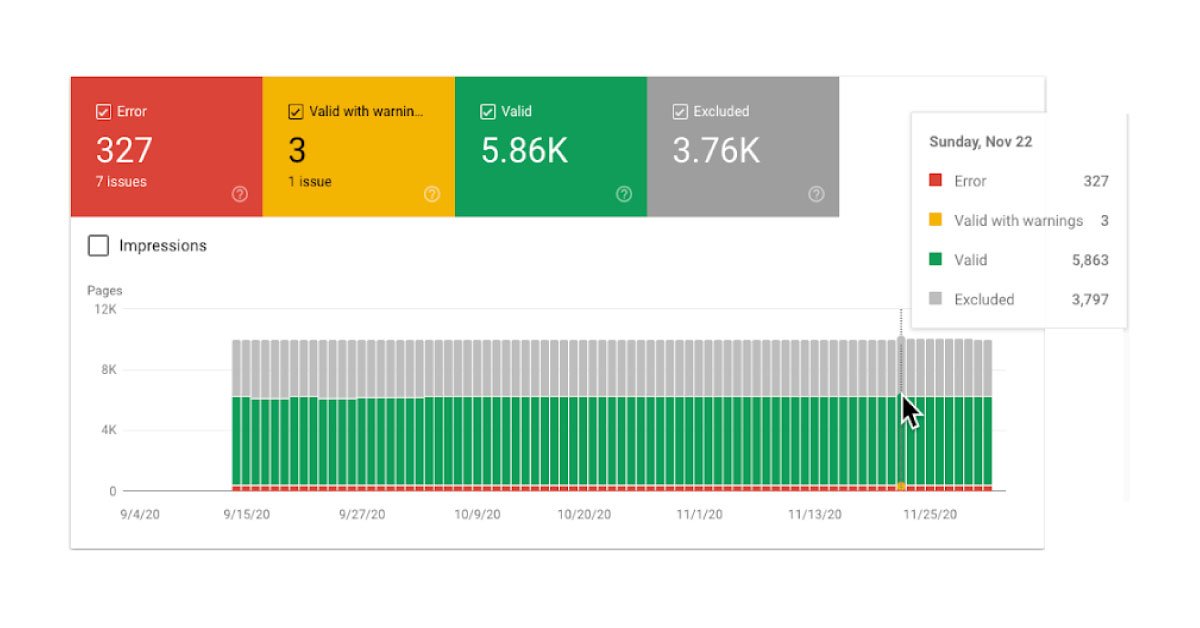
Firstly, you need to log in to the Google search console and choose your main domain from the drop-down list. Then you need to click on the coverage under the index to view the index. Then you will see the top part of the report features four tabs, including error valid with warmings valid and excluded. If you wish to check the mistakes, you must choose the error tab. The troubleshooting process will have two parts: first, identifying the errors and then understanding the mistake besides fixing them. You need to ensure that the only error tab is highlighted and then Scroll down to the details part.
Furthermore, it would be best if you noticed the errors that would be grouped into different categories. For example, the possible values would be server error redirect error submitted URL seems to be soft 404 or submitted URL blocked by robots, and submitted URL has some crawling issue. For each error category, you can see different validation statuses and trends besides the number of affected pages. You can then click on the row to see further details about the page concerned.
Different types of errors are as follows
Server Error 500
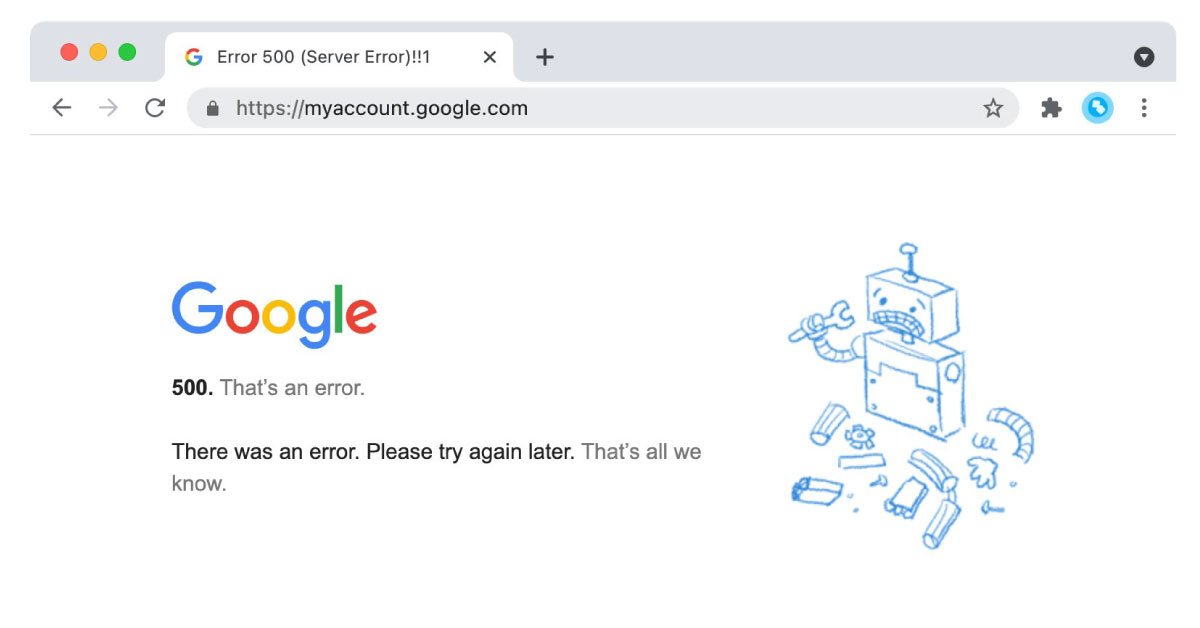
A 500-error means that something is wrong with your website server, preventing you from fulfilling your request. If that is the case, then you need to check the page in your browser and see if you can load it or not. If you can, then there are some chances that the issue has been resolved all by itself, but you need to confirm. If the server offers some outages, you need to email your eye team or the host company and ask for more details. You need to check what type of 500 status code is returning. At the same time, you need to verify that your server is not overloaded on misconfigured. Additionally, you need to ask the developers for help or contact the hosting provider. Lastly, you need to review the changes you have made recently to your site to check if any of them might be the root cause.
Fix a redirect error
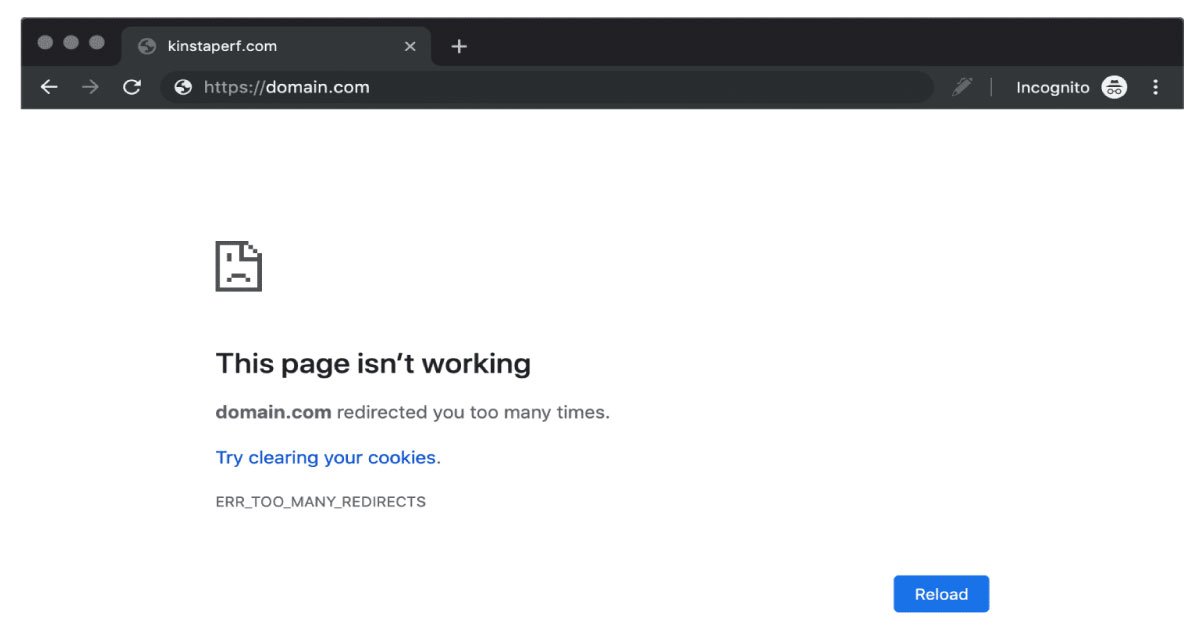
It basically means that your redirect is not working. A typical scenario is that your main URL has changed several times, so some redirects redirect to redirects. Google has to crawl a lot of content, so it doesn't waste a lot of time and effort crawling various links. It would be best if you solved this by ensuring that your redirect page directly goes to the final link reducing all the intermediate steps.
Submitted URL blocked by the robots
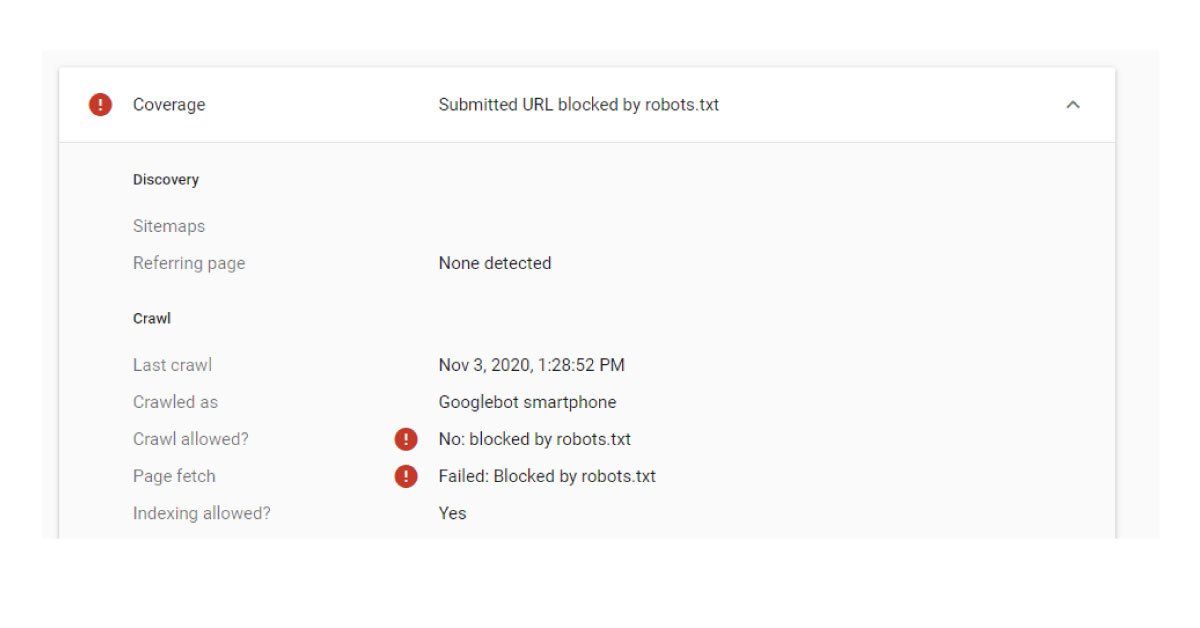
There is a line of code in the robots.txt file that notifies Google that it is not allowed to crawl through this page and even though you have requested the search engine to do so by submitting it to be indexed. You need to find and remove the line from this file if you actually want to be indexed. The WordPress plugins will sometimes sneak into pages in the sitemap file that doesn't belong. You need to upload an XML sitemap removing the URL if you don't want it to be indexed. On the flip side, you can change the guidelines in the file if you want it to be indexed.
The submitted URL was marked as non-index
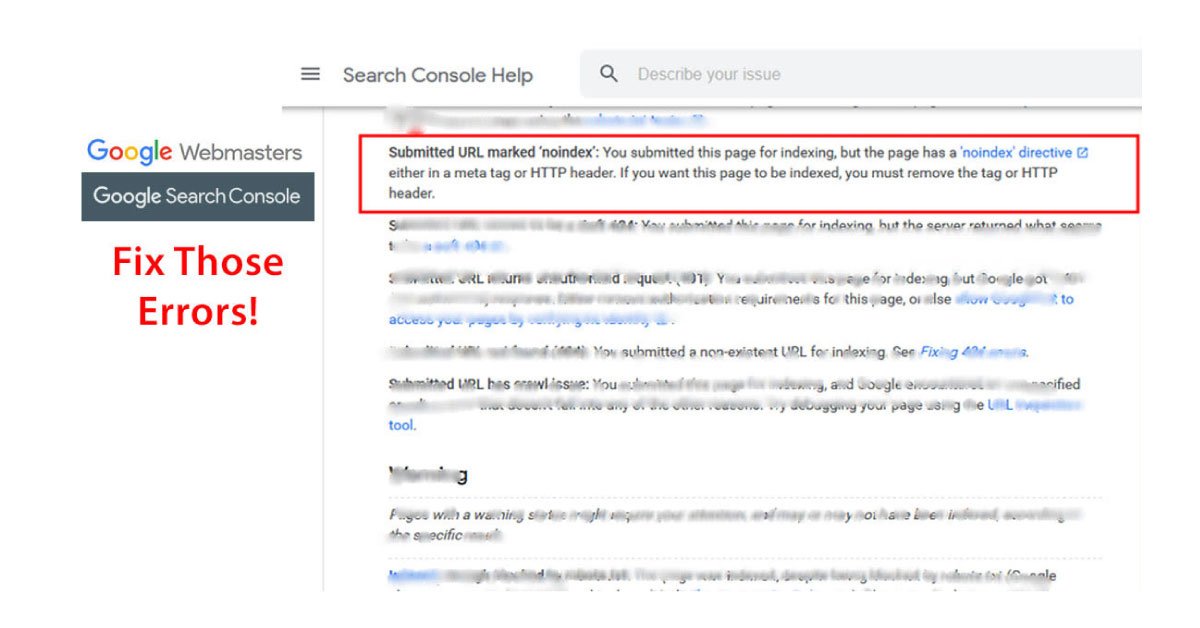
You might send Google some mixed signals if the submitted URL is marked as nonindexed. First, you need to check the page source code and look for the word non-index. Next, you need to go to the CMS if you see it and look for a setting that removes it or find some solution to modify the page's code directly. If you are not comfortable working with the developer tools, it might be possible to non-index a page through the HTTP header response through the robot’s tag, which is challenging to spot. You need to remove the non-index directive if you want the URL indexed. Eliminate the URLs from the XML sitemap if there are some URLs that you don't want Google to index.
The submitted URL returns an unauthorized request
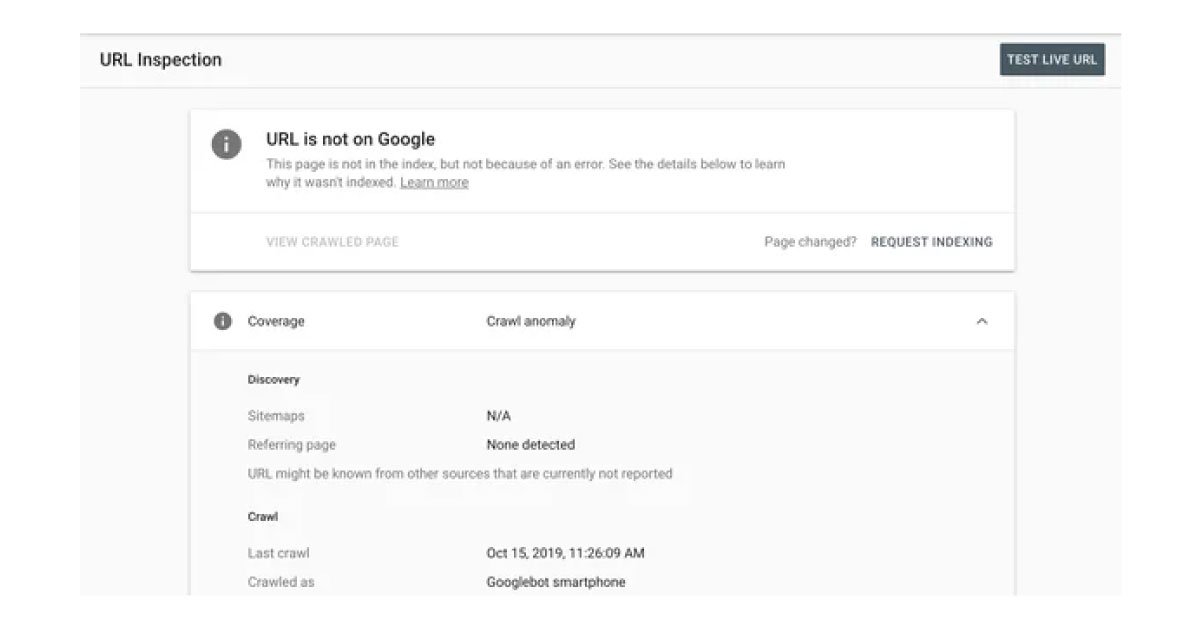
The warning is ideally triggered when Google attempts to crawl your page, accessible to only the locked-in user. However, you surely don't wish to waste Google's resources trying to crawl the URLs, so you need to find the location on your website where the linkage is discovered on Google and remove it.
The submitted URL was not found at 404
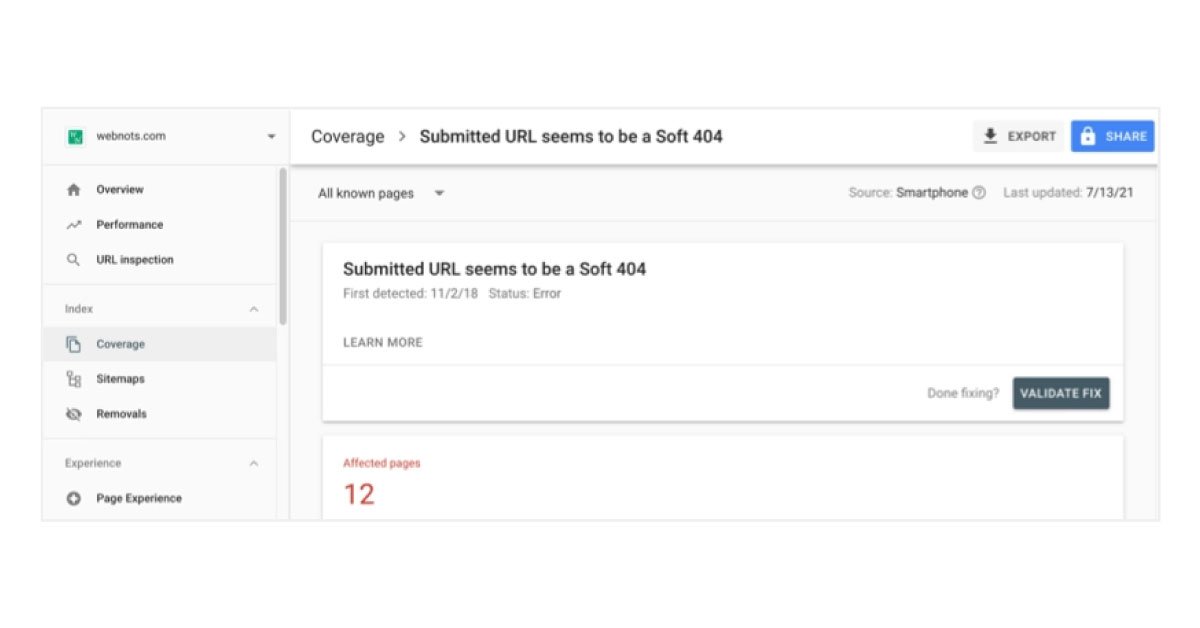
You are most likely to see this error when you remove a page from your website but forget to remove it from your site map. It can be prevented by regular maintenance of the sitemap file.
The submitted URL has a crawl issue
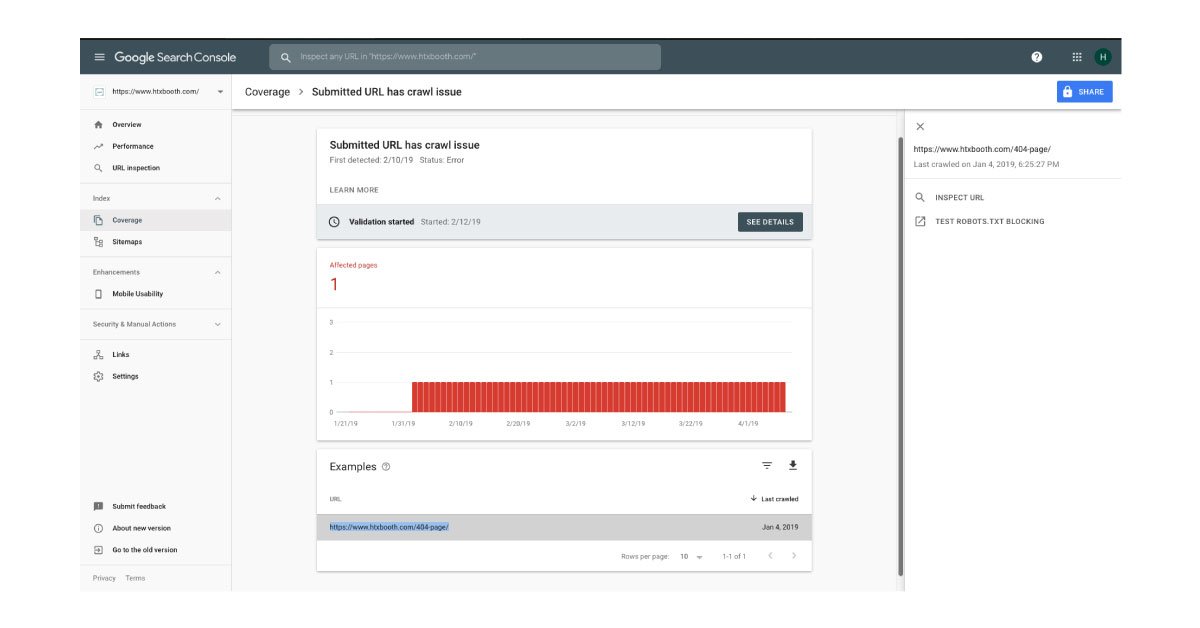
Something might have got in the way of Google's ability to download and render the content of your page completely. It would be best if you tried using the fetch as Google tool as the experts recommend and look for different discrepancies between what Google offers and what you see while you load the page in the browser. If your page depends heavily on JavaScript to load the content, it could be a problem. Several search engines also ignore JavaScript and Google is still not perfect. To get more information on what is causing the issue, you need to use the URL inspection tool. At times these errors are temporary, and they wouldn't require any action.
Excluded status
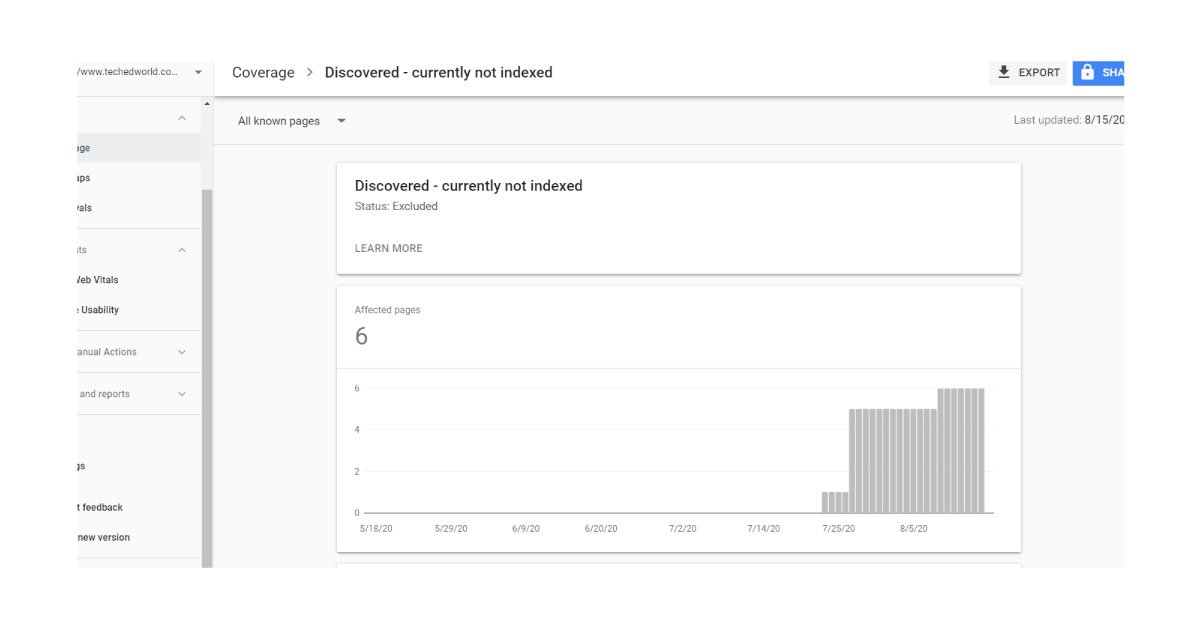
These pages are generally not indexed on the search results, and Google believes it is the right thing. However, here are some situations which are termed excluded.
Blocked by page removal tool

You might have submitted your amole request for the pages on Google search control. If this happens then, then Google attends the request for at least 90 days, so if you don't wish to index the page, you have to use non index directives and use non-index directives or remove the page.
Blocked due to unauthorized request
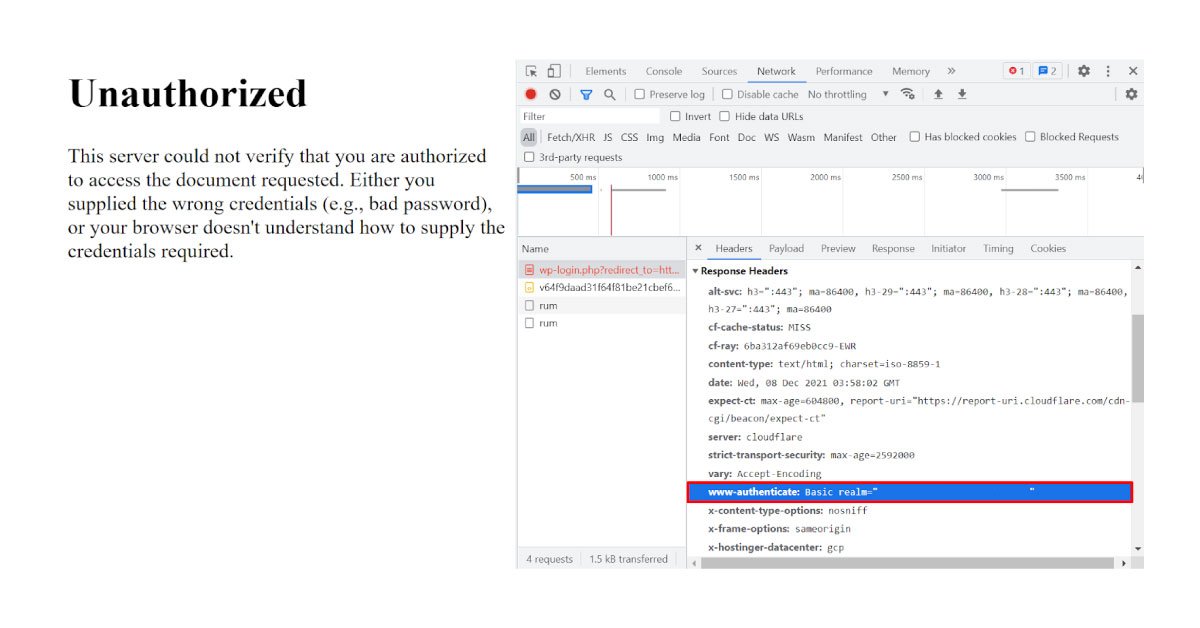
Using a request authorization, you are blocking the access to Google. If you want Googlebot to visit the page, you need to remove the authorization requirement.
Crawled now not indexed currently

This might be a situation when the page is crawled by a Google bot but is not indexed, and it might or might not be indexed in the future too. Therefore, you need to ensure that you provide valuable information if you want the page to be indexed in the search results.
Duplicate Google chose a different canonical than the user
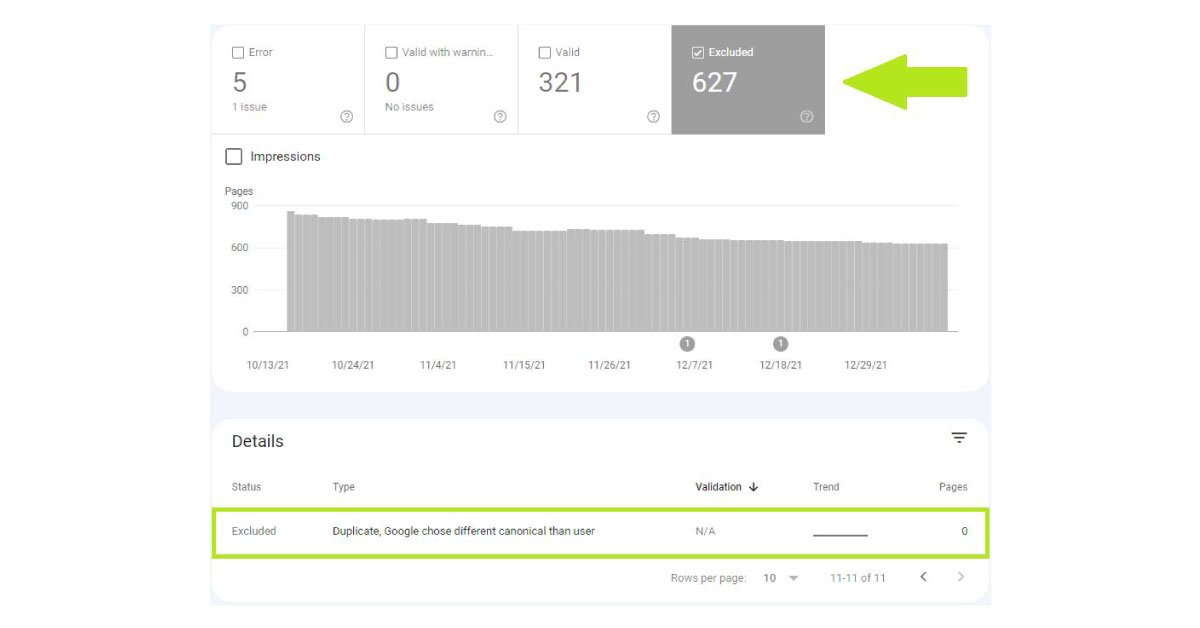
Google might have indexed another page that things function better as canonical while you have marked this page as canonical. In such a situation, you can either follow the Google choice and mark the indexed page as canonical and this one as the replica of the canonical URL. If that's not what you want, you need to find out why Google prefers another page over the one you have chosen and then make the necessary changes. Finally, you can use the URL inspection tool to discover the canonical page selected from Google.
Some of the most common index coverage report issues
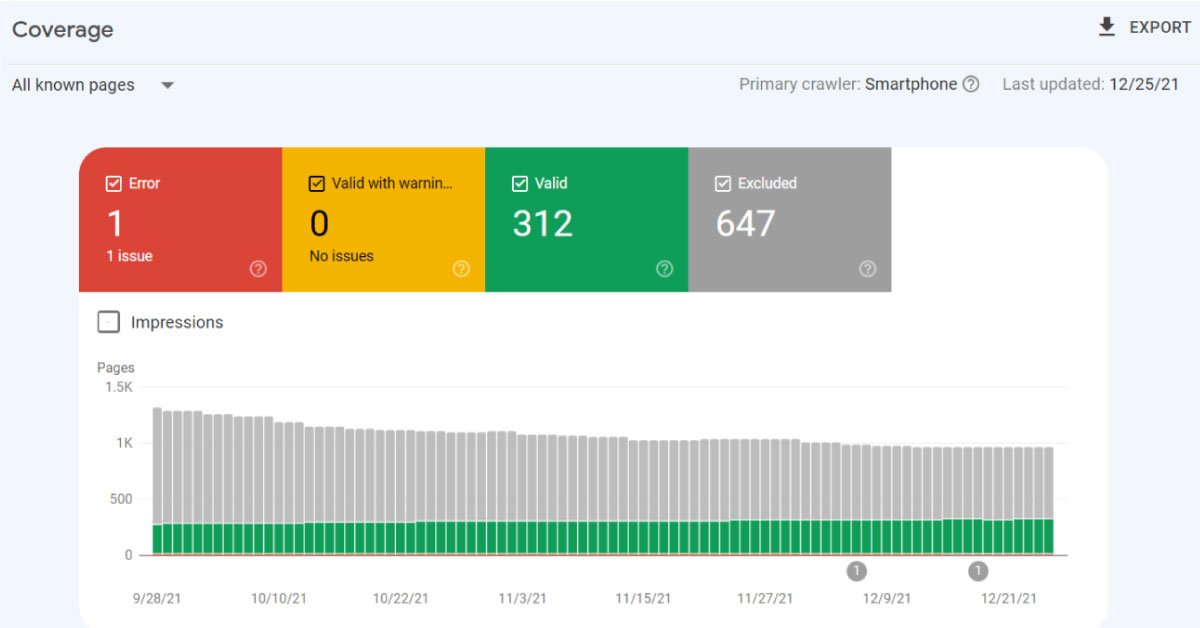
as you must know the different types of errors that you can find in the index coverage report and what steps you need to take when you encounter them. There are times when you would have seen excluded pages more than the valid ones. The condition ideally arises on prominent websites that have experienced a significant URL change. It would probably be an old website with a long history, or the code would have been modified.
When using the index coverage report, the first thing you have to do is to fix the pages that appear in the error status. It must be zero to avoid any penalties from Google. Additionally, you also need to check the excluded pages and check if the pages are that you do not want to index. Follow the guidelines given above if that's not the case. Finally, check the valid pages with a warning if you have time and ensure that the procedures you offer in the robot.txt are correct and there are no inconsistencies.



